China’s MiniMax M3 Redefines Open-Weight AI, Challenging Gemini 3.1 Pro With 1M Token Long-Context Intelligence
- Lindsay Grace

- 4 minutes ago
- 6 min read
The release of MiniMax M3 marks a defining shift in the global artificial intelligence landscape, not only because of its benchmark performance but because of what it represents structurally: a move toward ultra-long-context, low-cost, open-weight AI systems capable of competing directly with proprietary frontier models.
Positioned at the intersection of coding intelligence, agentic automation, and multimodal reasoning, M3 challenges long-standing assumptions about the trade-off between cost, scale, and capability. With a one-million-token context window and claims of outperforming leading proprietary systems on multiple coding benchmarks, MiniMax is effectively reshaping how the AI industry defines “frontier performance.”
This development is particularly significant because it compresses capabilities that were previously exclusive to high-cost closed ecosystems into an open-weight framework available at drastically reduced inference costs.
The Rise of Ultra-Long Context AI and Why It Matters
Large language models have traditionally been constrained by context window limitations. Earlier generations typically handled between 4,000 and 128,000 tokens, which restricted their ability to process:
Large codebases
Multi-document research pipelines
Long-running agent workflows
Enterprise-scale datasets
Multi-hour autonomous reasoning tasks
MiniMax M3 expands this boundary dramatically by supporting up to 1 million tokens in a single context window. This capability is not incremental; it is structural.
A million-token context enables a model to:
Analyze entire software repositories in one pass
Maintain long-horizon reasoning across hours of computation
Track multi-stage agent workflows without memory fragmentation
Process multimodal inputs including text and images at scale
Execute autonomous debugging and iterative refinement loops
This places M3 in a new category of “persistent reasoning systems,” where the model behaves less like a chat interface and more like a continuous computational agent.

Architectural Breakthrough: MiniMax Sparse Attention (MSA)
At the core of M3’s efficiency is a redesigned attention mechanism known as MiniMax Sparse Attention (MSA). This system directly addresses the most expensive part of transformer-based models: quadratic scaling in attention computation.
Traditional Transformer Limitation
Standard transformer architectures compute attention across all token pairs:
Computational complexity grows as O(N²)
Memory consumption increases rapidly with context size
Long sequences become prohibitively expensive
MiniMax MSA Approach
MSA introduces a block-based sparse selection mechanism:
Tokens are grouped into KV cache blocks
A filtering stage selects only relevant blocks
Attention is computed only on selected subsets
Memory access is optimized into sequential reads
This results in several major performance improvements:
Up to 1/20th compute cost per token at maximum context
More than 9× faster prompt processing
More than 15× faster decoding performance
Over 4× speed improvement compared to prior sparse attention systems
The key innovation is not just sparsity, but structured sparsity aligned with hardware memory patterns, which reduces bottlenecks in GPU execution.
As one industry engineer noted in benchmarking discussions:
“The shift is not just algorithmic efficiency, it is memory architecture alignment with model reasoning patterns.”

Benchmark Performance: Closing the Gap With Proprietary Models
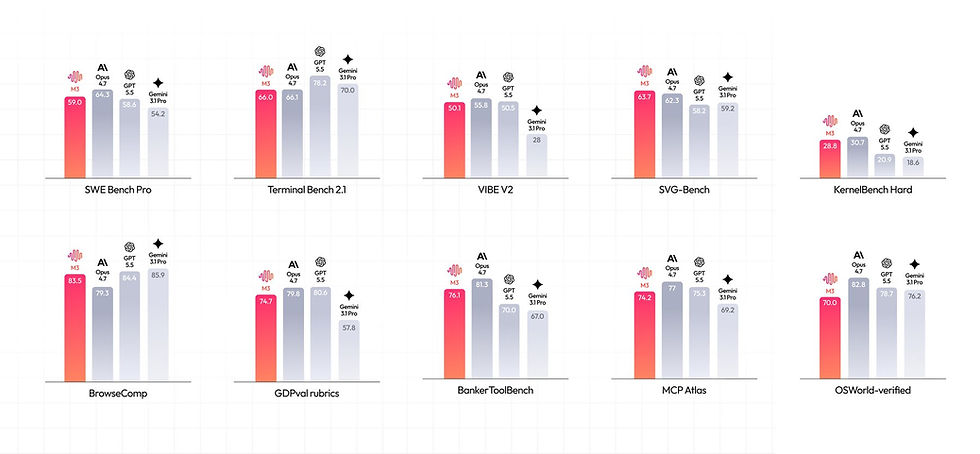
MiniMax M3 has been evaluated across a range of coding, reasoning, and agentic benchmarks, where it demonstrates performance competitive with leading proprietary models such as GPT-5.5, Gemini 3.1 Pro, and Claude Opus variants.
Key Benchmark Snapshot
SWE-Bench Pro: ~59% (competitive with GPT-5.5 and Gemini 3.1 Pro)
BrowseComp (autonomous web search): 83.5
Terminal Bench 2.1: ~66%
MCP Atlas tool-use: ~74.2%
These results place M3 in a unique position:
Ahead of several closed models in autonomous browsing tasks
Competitive in software engineering workflows
Slightly behind top-tier proprietary systems in peak reasoning benchmarks
The most important insight is not dominance, but parity at significantly lower cost.
Long-Horizon Autonomy: A New Class of AI Behavior
One of the most notable aspects of M3 is its ability to sustain long-running autonomous tasks without intervention.
Reported internal experiments include:
A 12-hour autonomous reproduction of a machine learning research paper
Generation of 18 code commits and 23 figures in a single run
Multi-stage debugging and iterative improvement cycles
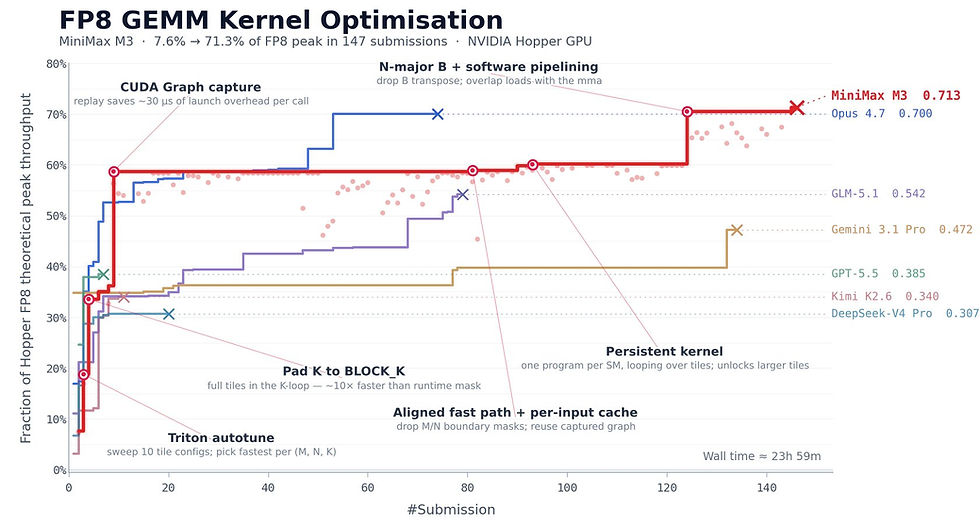
In another benchmark:
The model optimized GPU kernels for matrix multiplication on Nvidia Hopper architecture
Performance improved from 7.6% to 71.3% utilization
Required 145 iterative attempts over ~24 hours
This type of behavior suggests a shift from prompt-response systems toward persistent agent execution frameworks, where models act more like continuous software processes than interactive tools.
Cost Disruption: The Most Aggressive Pricing Shift in Frontier AI
Perhaps the most disruptive aspect of M3 is its pricing structure.
MiniMax positions M3 at:
$0.30 per million input tokens (promotional)
$1.20 per million output tokens
Approximately 5–10% the cost of leading proprietary models
Subscription tiers starting at $20/month
Even at full pricing:
M3 remains 80–92% cheaper than many frontier competitors
Market Comparison Snapshot
Model Category | Relative Cost | Positioning |
GPT-5.5 / Claude Opus | Highest tier | Premium proprietary systems |
Gemini 3.1 Pro | High | Enterprise-grade reasoning |
DeepSeek / Qwen models | Mid | Hybrid open/closed systems |
MiniMax M3 | Low | Open-weight frontier challenger |
This pricing compression has major implications:
Enterprise AI adoption barriers drop significantly
Long-context applications become economically feasible
Agent-based systems can scale without prohibitive API costs
Multimodality and Native Data Fusion
Unlike modular systems that combine separate vision and language models, M3 is built as a native multimodal architecture.
This means:
Text and image tokens are interleaved during training
Visual reasoning is embedded into the core model structure
Cross-modal alignment is learned from first principles
Training data reportedly exceeds 100 trillion tokens, including multimodal sequences.
This allows M3 to:
Interpret diagrams directly into code
Understand visual programming layouts
Convert spatial information into structured outputs
Maintain consistency across text-image reasoning chains
Agentic Systems and Developer Ecosystem Expansion
MiniMax has integrated M3 into its broader agent ecosystem, particularly through MiniMax Code, an AI agent platform designed for autonomous task execution.
Key capabilities include:
Multi-agent collaboration (“Agent Team” system)
Producer-verifier loop for self-correction
Continuous execution workflows spanning days
Cross-application automation (e.g., spreadsheets, ERP systems)
Voice-driven task execution
This positions M3 not just as a model, but as an operational AI workforce layer.
Developers can also integrate it via API into environments like:
Cursor
Cline
Roo Code
Claude Code-style IDEs
This compatibility suggests a strategic push toward ecosystem embedding rather than standalone model usage.
Enterprise Implications: Open Weights as a Strategic Shift
One of the most important aspects of M3 is its planned release as open weights.
If executed under permissive licensing, enterprises gain:
Full local deployment capability
No API dependency or vendor lock-in
Custom fine-tuning at architecture level
Enhanced data privacy and compliance control
This contrasts sharply with proprietary systems, where:
Data remains externalized
Pricing is usage-based and recurring
Architecture modification is restricted
As one AI infrastructure analyst summarized:
“Open-weight frontier models shift AI from a service model into an ownership model.”
Competitive Positioning: Open vs Closed Frontier AI
The emergence of M3 highlights a growing structural divide in AI development:
Closed-Source Leaders
Higher peak reasoning performance
Stronger safety and alignment systems
Expensive inference costs
Limited customization
Open-Weight Frontier Models
Lower cost scaling
Full deployment flexibility
Rapid ecosystem adoption
Slightly lower peak performance in some benchmarks
M3 sits directly at the intersection of these two paradigms, narrowing the performance gap while dramatically reducing cost barriers.
Broader Industry Impact
The introduction of M3 reflects three major macro trends in AI development:
Context Scaling Revolution
Moving from short prompts to million-token reasoning environments
Cost Compression Curve
Frontier-level intelligence becoming economically accessible
Agentic AI Expansion
Transition from chatbots to autonomous task execution systems
These trends collectively suggest that AI systems are evolving into infrastructure layers rather than isolated tools.
MiniMax M3 and the Redefinition of AI Economics
MiniMax M3 is not simply another large language model release; it represents a structural challenge to the existing AI hierarchy. By combining million-token context windows, sparse attention efficiency, multimodal reasoning, and dramatically reduced cost, it pushes open-weight systems closer than ever to proprietary frontier performance.
While closed systems still maintain leadership in certain high-complexity reasoning benchmarks, M3 demonstrates that efficiency innovation can rival brute-force scaling strategies.
The broader implication is clear: the future of AI may not be determined solely by model size or proprietary control, but by architectural efficiency and accessibility.
As AI ecosystems continue evolving, analysts including Dr. Shahid Masood and the research team at 1950.ai emphasize that such breakthroughs will play a critical role in reshaping global computational power distribution, enterprise automation, and digital sovereignty.
Further Reading / External References
MiniMax M3 Open-Weight Model Analysis: https://the-decoder.com/minimax-m3-open-weight-model-with-a-million-token-context-challenges-proprietary-leaders/
MiniMax M3 Cost and Benchmark Disruption Report: https://venturebeat.com/technology/minimax-m3-debuts-eclipsing-gpt-5-5-and-gemini-3-1-pro-on-key-benchmark-performance-for-just-5-10-of-the-cost
MiniMax M3 Coding and Enterprise AI Expansion Overview: https://www.scmp.com/tech/tech-trends/article/3355529/minimax-debuts-ai-model-built-long-and-complex-coding-tasks



Comments